About Me
Graduate of the School of Electrical and Computer Engineering of Technical University of Crete. I received my diploma (5-year curriculum) under the supervision of Antonios Deligiannakis.
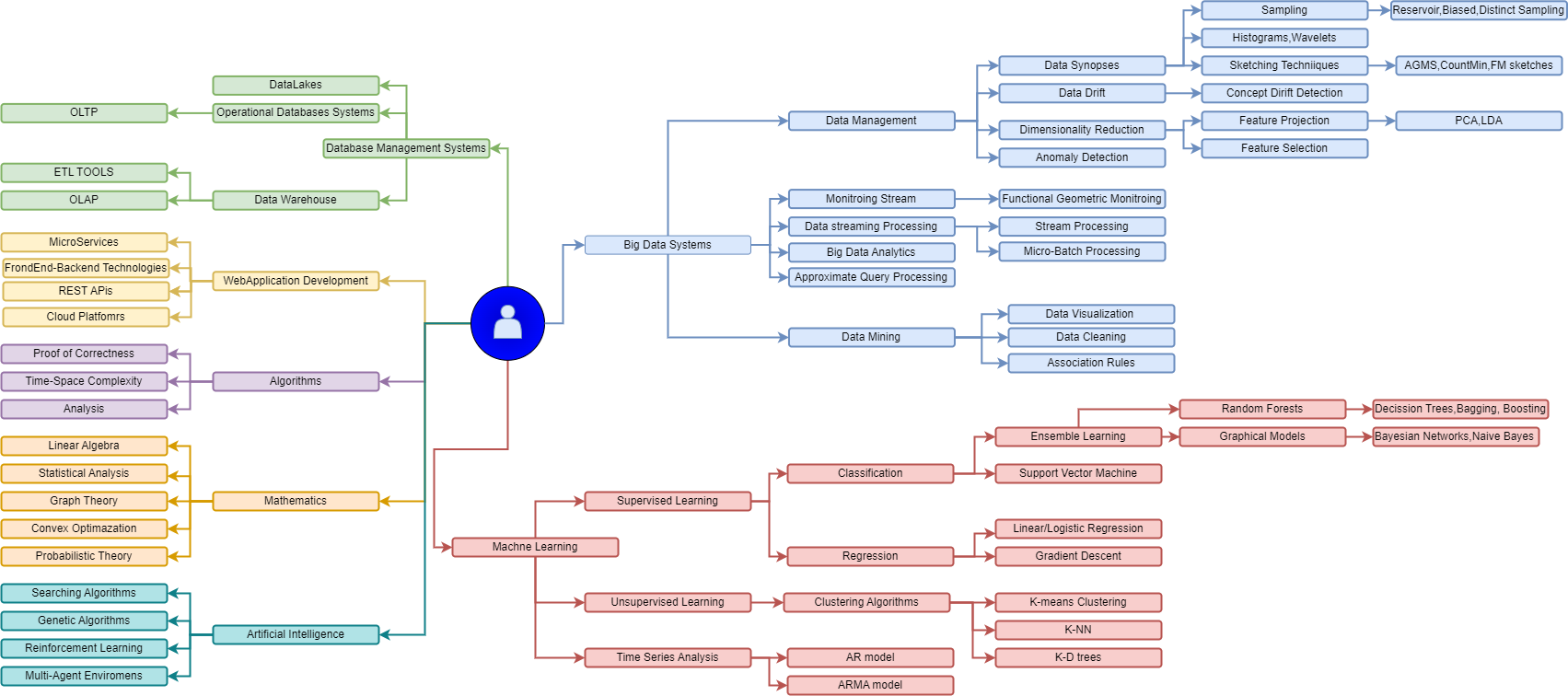
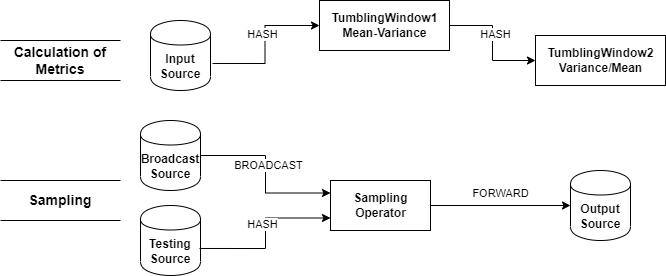
I have a strong interest in distributed data and streaming processing systems, as well as the design and implementation of end-to-end streaming and batching data pipelines, with a particular focus on cloud environments, though not limited to them. I am actively learning and working on Database Management Systems(DBMS), Distributed Data Processing Systems, Analytics over Big Data and last but least Distributed Machine Learning Algorithms. Currently, I am working as a Data Engineer around the Databricks Ecosystem on Azure Cloud Platform.
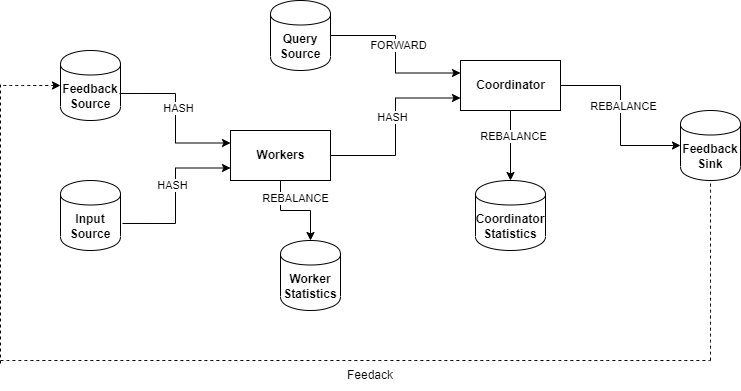
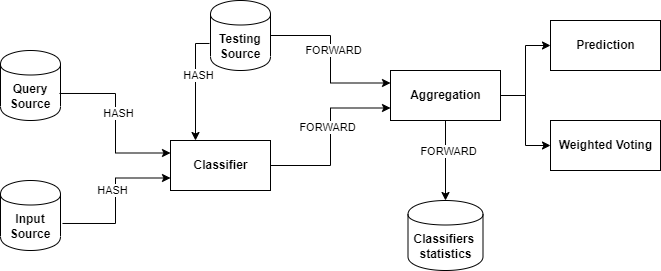
Regarding the machine learning algorithms, the whole idea boils down to the attempt of integrating machine learning algorithms into distributed streaming systems targeting to obtain the online/real-time version of machine learning algorithms, while providing high-performance and scalable systems capable of handling high-speed and distributed data streams. My latest work relied on Bayesian Networks and a special case of this, the well-known Naive Bayes Classifier. In particular, we focus on learning parameters of Bayesian Networks using the least communication cost under the umbrella of continuous distributed model. We proposed an alternative approach using the Functional Geometric Monitoring(FGM) method to have the online maintenance of networks(parameters) in distributed streaming systems.
Contact Details
Nikolaos Tzimos
Greece, 56123
nikostzim12@gmail.com